management: DASD Mirroring Part 3: Putting a Solution Together
In the previous article of this three-part series, we continued our look at DASD mirroring by looking at performance issues with PPRC and XRC mirroring. PPRC and XRC provide a second 'emergency copy' of your critical disk volumes. However simply having this copy isn't enough. You need the procedures and abilities to switch to these copies when you need. So how can this be done?
Basic Switching
Let's take an example: your disk volumes crash, and you want to switch to your alternate DASD. This sounds simple: you issue an XRC or PPRC command to switch from the primary to the alternate volume, and you're away.
But it's not that simple. For a start, you'll need to issue a command for every volume. If you've got a couple of hundred volumes that have failed, this will take some time. What's more, you'll want to confirm the status of each volume before switching over, and perform any corrective action on a failure. Or in other words, it'll take a few hours, and you'll probably have to IPL your production systems.
Automation is the key here. Some automation products such as CA Ops/MVS High Availability option provide an automation interface to PPRC and XRC. So you can create scripts to automate some of the hard work.
Basic Hyperswap
Perhaps a better solution is IBMs Hyperswap - providing you're using synchronous PPRC. A combined z/OS / hardware feature Hyperswap can automatically switch from a primary to an alternate volume based on criteria such as I/O errors; boxing a device offline, a control unit failure, or a user defined I/O timing threshold. And the good news is that this can all happen in a way that is transparent to applications: only a couple of seconds delay.
More importantly, Hyperswap will also automatically 'freeze' data replication to ensure that a valid copy of the data exists at the remote site before any cutover: the only thing worse than losing data is corrupting it.
Interestingly, Hyperswap uses either Tivoli Storage Productivity Center for Replication (TPC-R) or IBMs GDPS as a user interface, so you'll need one of these to work. TPC-R Basic Edition can be obtained for free, and provides single-site processing. The full product (not free) is needed when the DASD is in multiple sites.
The GDPS offering for Basic Hyperswap is called GDPS/PPRC Hyperswap Manager (GDPS/PPRC HM), and is the entry-level GDPS product.
Basic Hyperswap works great when there is a disk failure. However it can't help if there's a total system failure - it can't swap from one mainframe to another. For that, we need some extra smarts.
GDPS/PPRC
Suppose things are more serious, and you're entire primary site (systems and disk) are destroyed, and you need to switch to your backup site. Let's take PPRC for a start.
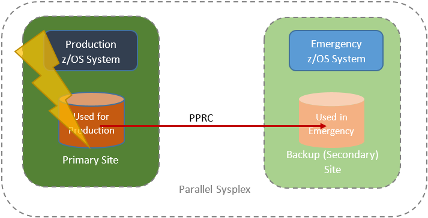
Hyperswap can't help you - it only switches disks, not systems. So we need to move up the GDPS totem pole to GDPS/PPRC.
For it to work, we need production and disaster recovery z/OS systems in a single parallel sysplex. GDPS/PPRC can do everything that GDPS/PPRC HM can do. However it can also move all processing from the production site to the remote site. It will automatically perform any IPLs or other processing necessary.
Like all GDPS products, GDPS/PPRC uses IBM System Automation for the automation part, though this can work alongside other automation products. And of course System Automation requires IBM Netview.
GDPS/XRC

In simplest terms, GDPS/XRC does what GDPS/PPRC does, but for XRC. With XRC you going to get some data loss as XRC is an asynchronous solution - a Recovery Point Objective of a few seconds. However it will do all the automation to switch from a primary site to a remote site.
There are a couple of differences. For a start, GDPS/XRC cannot automatically switch over if there is a primary system failure: an operator must manually start the process. GDPS operates alongside the SDM - either in the production or remote system. No parallel sysplex required between the production and remote systems.
GDPS/MzGM
GDPS/PPRC is excellent. Almost no data loss (a low recovery point objective, or RPO), and a quick cutover to the remote system if a disaster strikes (a low recovery time objective, or RTO). The catch is that GDPS/PPRC only works over short distances: a theoretical maximum of 200km, and a more realistic maximum of around 30km to minimize performance issues.
So if a disaster covers a 200km area (such as a hurricane), both sites are in danger. Those sites needing heavy-duty disaster recovery solve this problem by mixing PPRC and XRC. Here's how it works.

The production site uses PPRC to mirror DASD to a remote site less than 200km away. This remote site may be a full hot site with a second z/OS system, or just DASD. XRC is then used to mirror this intermediate DASD to a third hot site that is further away.
IBM GDPS supports the automation of this configuration by using both GDPS/PPRC and GDPS/XRC together into GDPS/MzGM (GDPS Metro z/OS Global Mirror).
GDPS/Metro Mirror
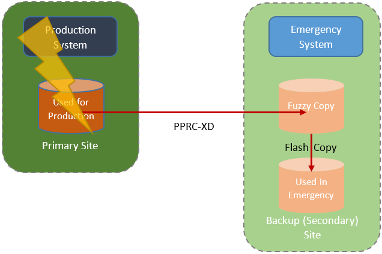
Metro Mirror uses a combination of PPRC-XD (asynchronous PPRC) and Flashcopy in a similar way to our three-site scenario mixing PPRC and XRC. This has the advantage of unlimited distances between primary and remote site, no SDM needed, and can also support non-mainframe disk devices. GDPS also supports this scenario using GDPS Metro Mirror.
Summary
In this article we looked at the basic GDPS offerings. There's further scope to create more robust environments with duplicated backups and remote data centres (3-site and 4-site options). If you look at the GDPS redbooks and articles, you'll only see them talk about IBM DASD. However the other storage vendors (HDS, EMC and HP) also support most of the GDPS and Hyperswap features.
In most cases, simply using DASD mirroring technology isn't enough. Procedures and automation need to be in place to quickly recovery from a disaster when remote DASD is needed. IBM GDPS today is really the only solution on the market that provides out of the box automation of many possible DASD mirroring scenarios to achieve the required RPO and RTO needed.
David Stephens
|
