technical: How to Implement Capping Without Pain
A few years ago, I saw a client implement capping. Unfortunately, they were too aggressive, and affected their users. Compile jobs started to take hours, response times were increased, and batch schedules took more time, affecting production processing. Such 'horror stories' can scare people away from capping. But it doesn't have to be this way. In fact, it shouldn't. So how can we implement capping to maximize savings, without impacting our critical systems and services?
Capping Strategies
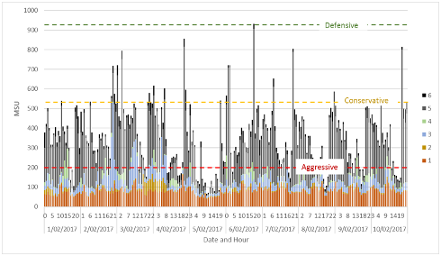
In our partner article, we talked about the three basic capping strategies: defensive, conservative and aggressive. Defensive protects from 'runaway' tasks increasing costs, conservative aims for modest savings without greatly affecting users. A more aggressive strategy aims for greater savings, understanding that users may be impacted. This last strategy aims to educate users to perform non-critical work outside of peak periods.
Whichever strategy you use, you will have a target capping figure. The chances are that you've used a graph similar to the one below, where the WLM importance settings are an indication of which workloads are more important, and which are less. So, importance level 1 (at the bottom) is very important, importance level 5 and discretionary (shown here as importance level 6) are not.
Step 1: Check WLM
The problem is that importance levels may not be a good guide. Importance levels are defined in the WLM service classes. Class definitions are often decades old, and are rarely checked or revisited. So, they may not be accurate or appropriate.
z/OS only limits CPU if there is not enough to go around. If there's lots of CPU, everyone gets as much as they want. So, if you've been running with capacity exceeding needs for many years, you haven't really been using the WLM features that limit CPU for lower priority workloads. It's possible that the WLM settings are out of date, and if the CPU is limited, high priority workloads may be starved.
In the above graph, it shows that the low importance work (importance 5 and discretionary) are a large quantity of the total workloads. So, a conservative strategy would be to cap at around 500 MSUs. In the periods where z/OS wants to use more than 500 MSUs of CPU, it will need to prevent some workloads from executing. You would expect that these workloads would be Importance level 5 and discretionary, but that may not be the case. Importance levels come into play when z/OS cannot meet WLM defined goals - it is not the primary value used by z/OS when deciding who gets CPU. So, the importance levels may be deceiving.
Before starting any capping, it's a great idea to review WLM settings and definitions, and make sure they're correct.
Step 2: Performance Metrics
Most sites will regularly create some key performance indicators (KPIs) for critical applications: CICS transaction response times, batch schedule elapsed times, TSO response times. These are essential; we'll want to check what these are and that they're still good indicators. But we'll want more.
Many sites keep metrics for critical applications and services, but nothing else. So, they may monitor IMS transaction response times, but not developer's TSO response times or COBOL compile times. Although these may not be in service level agreements, we want to monitor the effect of capping on all major users, not just production systems.
So, we need some fairly comprehensive statistics before capping as our baseline, so we can get an idea of what effect we're having.
In our graph above we're showing CPU usage over a ten-day period. In reality, this is far too short. Ideally, we'll want months of data to get an idea of seasonal or other movements. Information on planned future projects normally collected regularly by capacity planners will also be important when determining suitable capping values.
Step 3: Cap Defensively (in Development)
Now we're ready to start capping. There are many methods to actually implement capping, from limiting the logical processors available (hard capping) to setting MSU limits for LPARs (soft capping). There are also software products such as BMC iCap and zIT DynaCap. Whichever you choose, the implementation strategy should be the same. The first step is to set a defensive cap at around the current peak CPU usage. Why? It's more psychological than technical. Once capping is implemented (even defensively), it's no long a question of 'should we cap?', but 'what are the best capping parameters?'. It's also an easier sell to change control: a gentle first step. Finally, it gives confidence in the technology used to cap.
When thinking of capping, many don't think of development systems; they want to cap the big CPU user: production. However in a gentle implementation strategy, development is the place to start. Any capping issues have a far less effect in development systems, and you can gain confidence in the capping strategy and any capping-related reporting. I've even seen sites where they only cap development, not production.
So, now we have a defensive cap. We check our KPIs, which should be fine. We've implemented capping, and are ready to start getting some real savings.
Step 4: Start Squeezing
If you're not stopping at a defensive cap, this is the time to start reducing the cap. Many sites use a graph like we have above, and quickly set an aggressive cap to get the savings fast. However, this can cause problems. We've already talked about WLM issues, but there may be other issues that come up to cause some problems. For example, lower importance work needs to be done at some point. An aggressive cap may starve these workloads of CPU for a period of hours, or even longer. A gradual implementation is a far safer bet.
In our example above, we proposed that 500 MSU would be a good conservative capping target. So, to start we may first reduce to 700 MSUs. We still get a couple of hundred MSUs savings, but aren't squeezing too much at first. We then leave it for a month or so, and check our KPIs. We also recreate our graph with MSUs and WLM importance levels. If everything looks good, we may reduce a little more - say down to 600 MSUs.
Step 5: Monitor Continuously
This strategy of monitoring KPIs and usage, and then moving the MSU cap then continues. We will probably continue to slowly reduce the cap until we see some effect on our KPIs, or we hear complaints from users.
Capping is never finished - workload changes may mean that caps need to be released, or even tightened.
So far, we've only done this on our development systems. Hopefully they have similar WLM settings to production, so this has also been a good test for WLM. If everything is good, we can repeat the process for production.
Conclusion
What we've set out is a gentle, conservative capping implementation strategy. We slowly introduce capping to minimize the negative impacts, while gradually getting to our optimal capping value that maximizes our savings. This way, there are no surprises, and no sudden impact to users or critical services. Capping implemented without the pain.
David Stephens
|
