technical: Ten Things I See With WLM Configurations: And Really Don't Like
Whenever I start at a new site, one of the first things I do is to look at WLM to get an idea of how the performance is going. In our partner article, we show how. I've also done a few gigs where clients have asked me to take a closer look at WLM, and recommend changes. In some cases, the WLM setup is good. However, more commonly the WLM configuration could do with some work.
So, let me talk about ten things I often see when looking at WLM that I really don't like, and why.
1. PI Always > 1
Ideally, the WLM Performance Index (PI) should be 1: workloads achieving their performance goals. If a workload often has a PI far higher than 1 in the good times, it's unlikely that WLM will help when CPU becomes constrained. Also, we can't use PI to quickly determine if there's a performance problem with the workload.
Although workloads will sometimes have a PI of greater than 1, this shouldn't be the norm. If this occurs, either there's a performance issue, or the performance goal isn't right.
2. PI Always < 1
If the WLM PI is less than one, then you'd think that was OK: workloads are exceeding their performance targets. But there's a catch.
Let's say our CICS transactions have a performance goal of 90% completing in 1 second. If these transactions have a PI of 0.5, then they're completing in less than 0.5 seconds. This is great.
However, if the available CPU dries up, WLM won't help these CICS transactions until their response time increases beyond 1 second. Our CICS users will see these response times slow down. If this isn't a problem, then everything is OK. However, it's likely that users won't be happy.
I like to see all workloads regularly achieving a PI between 0.8 and 1.5. Outside of these, it's probably a good idea to take a closer look.
3. Things in SYSSTC That Shouldn't Be There
z/OS system tasks like the master scheduler are assigned to a service class called SYSTEM: this always has the highest possible dispatching priority (255). Critical system-related tasks like VTAM and JES2 are assigned to the SYSSTC service class: this gives them the second-highest possible dispatching priority (253-254).
However, some sites put inappropriate workloads into SYSSTC: like Db2 address spaces or CICS regions. This limits what WLM can do when there's not enough CPU to go around, and can even cause problems. At one site, they had a started task in SYSSTC that didn't belong there. This task went into a loop, locking up the z/OS system. An IPL was required to get out of it.
SYSSTC (and SYSTEM) should only be used for workloads that are essential for z/OS internal processing, or monitors like RMF. Other things should be assigned to other service classes.
4. Too Many Service Classes and Periods
When WLM decides that it must make a change because there isn't enough CPU, it will change the z/OS dispatching priority of two service class periods: one gets an increase, one gets a decrease. However, WLM only does this every ten seconds.
So, if a z/OS system has 50 active service classes and periods, then some of these will never get any WLM help. Ideally, the number of active service classes and periods shouldn't be more than 25-30.
5. Complicated Workload Selection Criteria
z/OS administrators use selection criteria to group workloads into service classes. This criteria can be based on lots of things, including the address space name, CICS transaction name, or JES job class.
At one site, they had a rule for a service class based on job name that had over one thousand entries: that's right, one THOUSAND. Some were full job names, others were patterns. These entries were not listed in alphabetical order, they were just added to the end when necessary.
If workload selection is too complicated, it's too complicated. Too hard to manage, and it gets harder to ensure that workloads have the right service class. In the case above, every new job required a review of the WLM configuration, and often a change.
I like to see simple, straightforward workload selection rules. If coding these for jobs, JES job classes may be a better option than manually listing every job that is eligible.
6. Not Using Importance
Every service class and period are assigned an importance level indicating exactly that. This value is, well, important. WLM will try to help high importance workloads first. In most z/OS systems, there is always some workloads that are more important than others.
Take a look at this graph, showing CPU usage and importance.
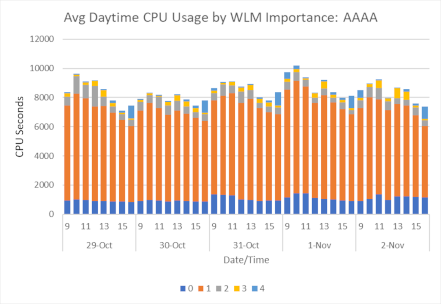
In a nutshell, almost all the work running on this system is importance 1. WLM cannot prioritise workloads if CPU becomes constrained: the WLM configuration hasn't identified any lower priority workloads that consume CPU.
It's unusual for a z/OS system to have no low-importance work running. For example, the following graph is a little better:
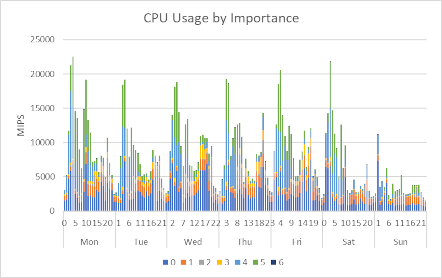
CPU usage is better distributed amongst importance levels. I like to see this sort of graph: if CPU becomes constrained, our important workloads can continue with no impact on performance.
7. Incorrect Importance
At one site, they had a CICS/Db2 application. However, the CICS region had a higher WLM importance value than the Db2 address spaces it used. If CPU becomes constrained, WLM may give more priority to CICS than Db2. But this won't help: CICS will still wait for Db2.
Tasks that provide services should have a higher importance than tasks using those services. So, IRLM should have a higher importance than client IMS and Db2 subsystems. IMS and Db2 should have a higher importance than address spaces using them.
8. Anything in SYSOTHER
The SYSOTHER service class is used for workloads that have not been assigned a service class. This usually indicates that the WLM configuration has missed this workload. What's worse, these workloads are discretionary: they get CPU if no other workloads want it.
I believe that WLM should be configured to assign a service class (that is not SYSOTHER) for all workloads. SYSOTHER should be regularly monitored for workloads that fall through the cracks.
9. Not Using Response Time Goals
I often see CICS regions that use velocity performance goals. In my opinion, velocity goals should be the last resort: response time goals should be used where appropriate. In particular, online workloads like Db2 DDF, IMS and CICS should normally have response time goals. These can be aligned with service level agreements and response times expected by users.
10. Over-Using Response Time Goals
In some cases, response time goals aren't appropriate. For example, at one site they had a CICS region processing incoming IBM MQ messages. Long-running transactions would 'listen' for incoming messages, and then continue to process these incoming MQ messages until no more were waiting in the queue. This is an example of a transaction where response time goals don't work.
Ideally, such 'background' tasks should be in different address spaces to 'client facing' tasks where the response time of the task is relevant. Background regions can be assigned a velocity goal, the client facing tasks a response time goal.
Conclusion
z/OS WLM is fantastic. Correctly configured, it can protect important workload performance when resources (particularly CPU) are constrained.
David Stephens
|
