LongEx Mainframe Quarterly - May 2020
In an article in our previous edition, we talked about how we had been working with a client to implement Sysplex for their CICS applications: modifying the system to enable Sysplex features, and applications to use them. During this project, our focus was on the online CICS programs: changing them so they can run in multiple CICS regions. But as we dug deeper, we found other areas that, with minimal changes, could benefit from our new Sysplex. Let's look at some of them. Our New CICSPlexBefore we get started, let's look at what we've bought. Here's a diagram of our 'new' CICSPlex configuration. 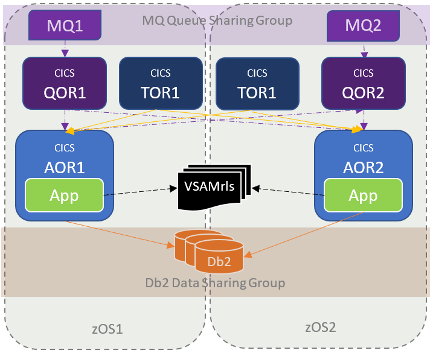
Two CICS AORs (one on each z/OS system). Incoming MQ workloads from a queue sharing group (QSG) triggered using queue owning regions (QOR). These regions also managing incoming web traffic. Incoming 3270 traffic through terminal owning regions (TORs). Our applications use VSAM (now VSAMrls), and DB2 in a data sharing group. Nice. Ok, so what extra benefits are we talking about? 1. Remote VSAM AccessOther CICS applications peeked into some of our VSAM datasets using CICS function shipping. Or in other words, they defined a file in their CICS region as remote, pointing to one of our CICS regions where the file was opened. These applications weren't getting any benefit from CICSPlex. If the one CICS region they were pointing to failed, they would lose connectivity. For one application, we changed their CICS file definitions to local RLS. Now they don't need any CICS region to be active. However, this approach wasn't feasible for all applications. For example, some were in a different Sysplex. For these, we created a file owning region (FOR) to improve their resilience. Our article on VSAM issues explains this more. 
2. Remote DB2 Data SharingMany remote applications accessed our Db2 data via DDF. Most of this was JDBC, but some other methods as well. These had a specific z/OS system and Db2 subsystem in their connection parameters. As we now had a data sharing group, we worked with them to benefit from it. We changed the connection parameters to use a DVIPA address (shared by multiple z/OS systems), and specify the Db2 data sharing group. If one Db2 subsystem is unavailable, they continue to process on the other. 3. Remote Program CallsOther applications called our CICS programs and transactions. Some were performing a remote call from a different CICS region. These were easy: change the program/transaction definition to DYNAMIC(YES) ROUTABLE(YES), and let CPSM handle the routing. This wouldn't work for a call from outside our CICSPlex. Fortunately, we didn't have any of those. Other non-mainframe applications were accessing our local CICS using CICS ECI. The solution: change the remote application to use a DVIPA address, so it can connect to either CICS region (each CICS region listened to the same TCP/IP port number). 4. Web RequestsWe used Circle C/Flow for web requests. We changed the non-mainframe component to specify a DVIPA address of our QORs, which in turn routed to the best CICS AOR. We also used Rocket Shadow. A similar solution for this, as well as defining an alternate application ID for every Shadow connection: if one QOR failed, Shadow would use another. 5. Transactions From BatchSome batch programs called a CICS transaction using batch utilities like CAFC. For these to succeed even if one CICS region was down, we changed to job to connect via a VTAM Generic Resource to our terminal owning regions (TORs), which in turn routed to the best CICS AOR. EXCI was a little different. We did have some programs using the DB2 DSNACICS stored procedure, which connected to one CICS region using EXCI. There is no easy solution here, so we decided to change the remote application to use web services. There were no other EXCI users. But if there were, we would have had to modify the remote programs to perform error handling if one region was unavailable. 6. Remote MQThere were lots of remote MQ connections to our MQ queue managers. These were converted to shared queues and channels. However, the 'remote' end also needed to be changed. Channel definitions for remote queue managers were changed to use the MQ queue sharing group, and DVIPA addresses. Remote MQ clients were also changed to use the DVIPA and the MQ queue sharing group. 7. Batch AffinityDidn't think that CICS would affect batch, did you? However, many of our batch jobs were tied to a single z/OS system using the /*JOBPARM SYSAFF= JCL statement. If the z/OS system failed, batch would not run, affecting the application. We implemented WLM scheduling environments for Db2 data sharing and MQ queue sharing. Now, jobs using MQ/Db2 specify the relevant WLM scheduling environment. If MQ/Db2 is down, automation rules disable the scheduling environment. The offending SYSAFF statement was removed, so the job can execute on any suitable system. ConclusionSimply setting up a CICSPlex for our in-scope applications provided resilience for the CICS applications, but nothing else. However, some small changes to other CICS and non-CICS components outside of these applications enabled them to also benefit from our new Sysplex configuration. |