technical: Disk Mirroring Part 1: A Review of XRC, PPRC and Friends
Every heard of PTAM? It stands for Pickup Truck Access Method. This is where you load your backup tapes onto a truck and transport them to another site when you lose your data centre. At that remote site, you restore your production systems and continue processing.
There are two problems with PTAM. Firstly, it's slow. I used to work for a company that would regularly do PTAM DR tests. It took 48 hours. The second problem is that you only restore data to the last backup. So if you take daily backups that go offsite, you've lost all the changes from that last backup. If PTAM doesn't work for you, you're going to need to mirror your DASD - continuously create an up-date copy. In this first or three articles, we review the options to achieve this.
z/OS Global Mirror
In 1994, IBM announced the 3990-6, the latest DASD controller for 3380 and 3390 DASD. Although it took them a year to deliver the new controller, it provided a new features for mirroring a DASD device to a remote location: Extended Remote Copy (or XRC).
Today XRC is called z/OS Global Mirror, or zGM for short. But most technical people still call it XRC (including us). So here's how it works:
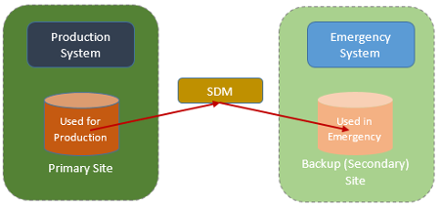
There are two systems: a primary system that runs production, and an emergency or recovery system. The recovery system has one disk volume for every production volume to be mirrored. A system data mover (SDM) detects all updates to each production volume, and re-does them on the corresponding recovery volume. So you have a disk at the DR site that is pretty much the same as the production volume.
SDM is really another name for DFSMSdfp running on z/OS - this is what does the heavy lifting in terms of moving updated data between primary and backup volumes. So XRC is a combination of DASD and z/OS software. In the diagram SDM is in the middle of the two systems. In reality the SDM could run on either
- The production system (if it is z/OS)
- Another z/OS system at the primary site
- The emergency system (if it is z/OS)
- Another z/OS system at the backup site
Normally you'll want SDM at the backup site. Although the SDM runs on z/OS, it isn't limited to z/OS DASD. It can also mirror z/VM and z/Linux (both running native, and as a z/VM guest) disk volumes.
With XRC, there is no theoretical limit as to the distance between primary and backup site. Anything less than 100km can use FICON links between them. Anything over 300km or so will need a channel extender: allowing FICON to work over TCP/IP networks. There are a couple of vendors selling these extenders including Brocade and Cisco.
Although XRC was introduced with the IBM 3990 disk controller, it isn't an IBM-only option. Both EMC and HDS also support XRC. In fact you could mirror an IBM disk volume to an EMC volume.
XRC is an asynchronous solution. This means that when an application does an I/O, it doesn't wait for that I/O to complete on the remote system. So if the production system were to fail, the remote system maybe a little behind the times. How far behind depends on several things, including XRC performance, network bandwidth (if using channel extenders), and the distance between the data centres. It's possible for the remote disks to be a couple of minutes behind. This is data lost if a disaster happens. For some organisations, a couple of minutes isn't good enough.
Metro Mirror
When the IBM 3990-6 controller was announced in 1994, it didn't just introduce XRC. It also introduced Peer-to-Peer Remote Copy (PPRC). Today PPRC is called Metro Mirror, but we still call it by its old name. PPRC was a little different to XRC. Here's how it worked:
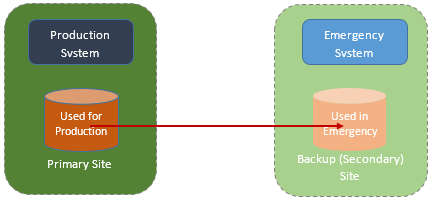
The diagram looks pretty boring doesn't it? Just a line from the production volume to the backup volume. PPRC doesn't use DFSMSdfp or z/OS. In fact, it is completely removed from the operating system (though there are z/OS commands to control PPRC). Rather, it is a solution implemented by the DASD controllers. So the DASD controllers (included in DASD subsystems today) detect changes to production volumes, and instruct the remote controller to re-do them.
PPRC is a synchronous solution. So when an application writes to a production volume, it must wait for that write to be made to the backup volume. In fact, the DASD controller won't even pass control back until the write is complete on both primary and backup systems.
The good news is that you won't lose a minute or two of data if the primary system goes down: the emergency system will always be up to date. The bad news is that this is expensive. In one site, we have seen I/O service times increase by a factor of 5 for a PPRC link over 30km (about 20 miles).
This brings a second limitation to PPRC - distance. Theoretically, you can have a PPRC link over any FICON channel (no channel extenders) - so you can have the two sites up to 300km apart. In practice, this is too far, so your backup site must be closer.
Both HDS and EDS have their own facilities to do the same processing as PPRC: TrueCopy for HDS (also known as Hitachi Remote Open Copy, or Hitachi Remote Copy), and SRDF (Symmetrix Remote Data Facility) respectively. However they don't mix. So you can't mirror an IBM volume to an HDS volume at a remote site.
Global Copy
In 2002, IBM announced PPRC-Extended Distance (PPRC-XD). This is basically PPRC, but asynchronous. So the DASD controller at the primary site will replicate DASD updates at the backup site without z/OS intervention. However the application doing the I/O doesn't need to wait. Today this is called Global Copy. However PPRC-XD has a problem - it's a fuzzy backup. The DASD controllers can't guarantee integrity. So if the primary site fails, the backup site may not be workable.
To fix this, PPRC-XD is used with Flashcopy (IBMs way of instantly making a copy of a disk). Here's how it works:
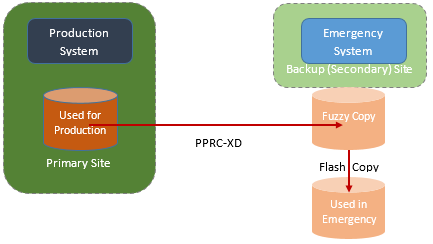
PPRC-XD makes asynchronous backup. However periodically the primary and backup controllers communicate to make a consistent copy at the backup site. When this completes, a copy of this consistent copy is made using FlashCopy. This is the volume to use in an emergency.
Today PPRC-XD is called Global Copy. When combined with FlashCopy it is called Global Mirror (previously Asynchronous PPRC). Again, HDS offers a similar TrueCopy Extended Distance (also called Hitachi Universal Replicator), and EMC SRDF/A (SRDF/S is sometimes used for the synchronous copy feature of SRDF).
Conclusion
So now we can get an up-to-date (or almost) copy of our primary disk at a remote site. However the performance of XRC and PPRC can be a big issue. In our follow-on article, we'll look at the performance of DASD mirroring, and its impact on production systems.
David Stephens
|
