technical: Disk Mirroring Part 2: Performance
In the first article of this series of three, we looked at the basics of DASD mirroring: XRC and PPRC (or Metro Mirror and Global Mirror as they're now known). And this technology is great, providing a continuously updated copy of a disk on another subsystem at a remote location.
What you may not have thought of is that performance of XRC and PPRC are important, but for very different reasons. So in this article, we're going to look at XRC and PPRC performance.
XRC Performance
So we have our XRC systems: the z/OS data mover (normally at the remote site) automatically replicating data updates from one set of DASD to another:
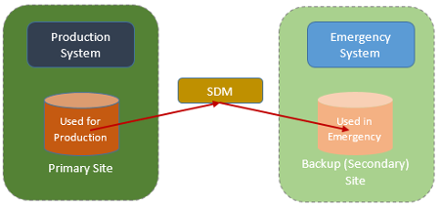
When we talk of XRC performance, we are concerned about two issues:
- The amount of data in-transit
- The effect on production performance
Data In-Transit
Assuming the updates are constantly being performed on the primary disk subsystems, there will be data that is 'in-transit': that has been updated on the primary systems, but not the remote systems. This data is the data that will be lost in the case of a failure of the primary systems. Ideally, we want to minimise the amount of this potential lost data.
This can be done by transferring data as fast as possible between the primary and backup systems. There are a couple of factors that impact this:
- The distance between the primary and remote subsystems.
- The speed of the data link between the sites.
- The performance of the z/OS data mover.
There isn't much we can do about the distance issue. However the speed of the data link between the two sites can be improved: by improving the telecommunications infrastructure such as channel speeds and hardware. Both Brocade and Cisco offer optional features to further accelerate XRC transmission and improve the performance of the data link.
As XRC uses the DFSMS SDM as the data mover, the performance of z/OS and the DFSMS SDM are understandably really important. Most sites will use DFSMS on the remote site as the data mover for two reasons: production workloads cannot impact the performance of this remote SDM, and similarly, SDM processing cannot impact production performance.
Impact on Production
The second area of XRC performance is its impact on production and production costs.
If running DFSMS SDM on the production systems, this processing could possibly impact production as DFSMS SDM chews up CPU and other resources. The CPU consumption may also increase software licensing costs, though some of the XRC load can be offloaded to zIIP processors.
Even if running DFSMS SDM on a remote system, XRC performance could impact production performance. The worst case scenario for XRC is if XRC cannot keep up with production updates. For example, suppose the production system performed 10,000 updates a minute on a production system. If XRC can only transfer 8,000 updates a minute, then it simply cannot keep up with the production workload.
In some cases this will be normal for short periods of time: for example disk defragmentation or full disk copy operations. Other times it will spell trouble. XRC has a couple of ways of solving this.
The simplest way is to do nothing and leave things as they are. This way a site has no control over the data 'in-transit' - it could vary dramatically. If the in-transit data becomes too high, the 'link' between primary and backup device pairs could be suspended. In practice most sites with XRC have some target recovery point objective (RPO) - the maximum period where data could be lost.
For a long time XRC has provided a facility to block all I/O to a device for short periods if the amount of in-transit data exceeds a threshold: data blocking. Data blocking thresholds can be controlled by parmlib settings, and switched on or off for different volumes as appropriate. A more elegant solution is write pacing, which slows down writes (rather than stopping all I/O). As the amount of waiting updates increases, the performance of production updates can be further decreased. Again, write pacing is controlled in parmlib members, and can be enabled or disabled as required. The XRC command XQUERY VOLUME_PACE produces a report on write pacing.
Workload-based write pacing is another step up, using WLM to tailor pacing options to subsets of address spaces or applications.
Blocking and write pacing are features to manage the I/O degradation if XRC cannot keep up with the number of incoming DASD updates. Either way, ideally XRC should comfortably be able to handle all updates, even in peak times. A first step in doing this is to look at the telecommunications infrastructure, and making sure that it is up to the job.
However there are other resources that need to be thought of. The XRC address spaces (including the DFSMS SDM) need to have sufficient CPU to operate - so their priority must be set correctly in WLM. Similarly the DFSMS SDM address spaces needs memory. The maximum number of buffers assigned can be set using parmlib settings - ensuring that enough buffers are available is important. Page fixing these buffers and other memory using the parmlib PermanentFixedPages parameter can also improve performance. There are several other parmlib settings that can impact XRC performance. A list of current XRC parameters can be obtained using the XQUERY command.
XRC writes updates to a journal before applying them on a remote system. So journal performance can impact XRC performance. There are things that can be done to maximise the performance of these journals, including defining them as striped datasets, putting them onto their own disk devices, and spreading them across disk volumes.
PPRC Performance
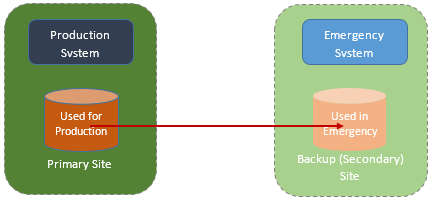
This is the same boring diagram from the last article, showing how PPRC works: a simple link wher the data movement is handled by the DASD controllers in primary and remote sites. So although the telecommunications infrastructure between these controllers is important, there is less to tune than XRC.
For synchronous PPRC, the impact on production performance is the key issue. The graph below compares the average I/O time of a write with, and without synchronous PPRC.
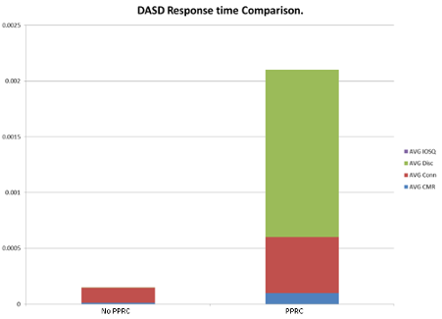
It's a big difference isn't it? The synchronous PPRC has increased the total average I/O wait by a factor of 5. You can see that most of the time increase is from Disconnect time (in green). The connect time (brown) has also increased, though this is probably because the no-PPRC example used z/HPF, whereas the PPRC example did not. This example is for a site where the primary and backup site were approximately 50 km (30 miles) apart. The difference (overhead) would increase markedly if the distance between the two sites was further increased.
So what can we do? The bottom line is: not much (unless you can make the distance between the two sites closer). We can make sure that the telecommunications infrastructure is the best we can make it. We can make sure that we configure the I/O as best as possible, and use features such as z/HPF to improve performance on the primary system as much as possible. And we can make sure that only disk volumes that really need the availability provided by PPRC are mirrored. But that's about it.
Conclusion
That's right - PPRC and XRC aren't necessarily straightforward (is anything with the mainframe?). One of the important issues when configuring this mirroring technology is performance - managing the potential data loss, and the impact on production systems.
David Stephens
|
